The Index Is The ____________ Of A Piece Of Data.
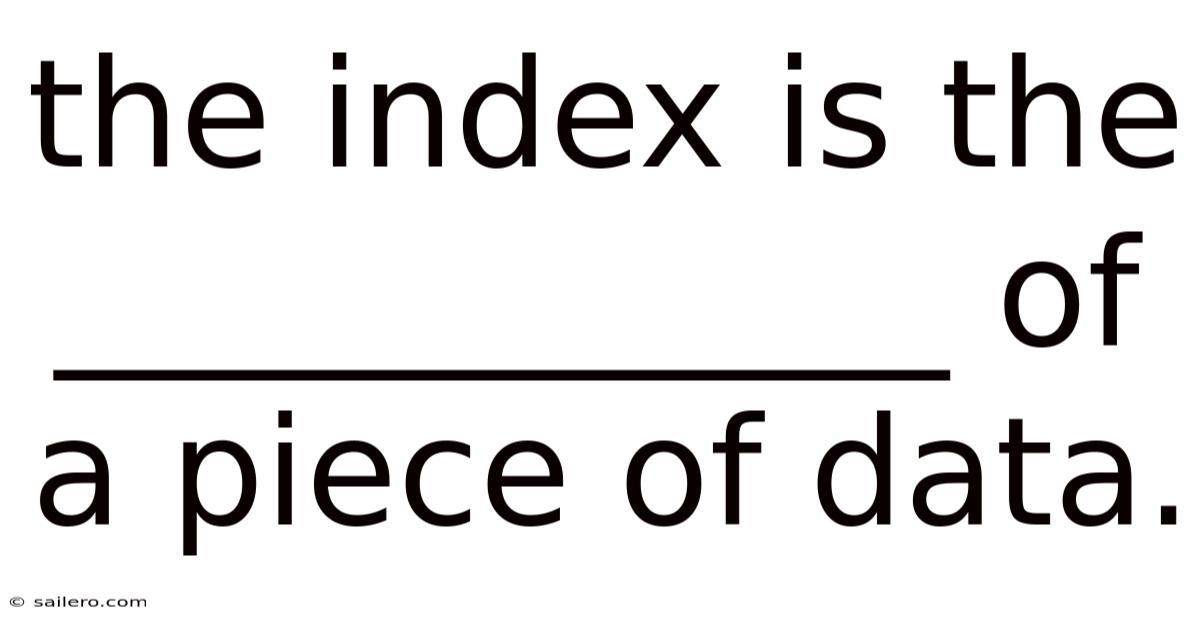
The index is the address ofa piece of data, a fundamental concept that underpins how information is located, retrieved, and organized within databases, file systems, and even everyday digital interfaces. Understanding this relationship illuminates why indexes are indispensable for performance, scalability, and usability across a wide range of applications, from simple spreadsheets to massive distributed data warehouses.
What Exactly Is an Index?
An index functions much like the index at the back of a book: it provides a rapid roadmap to locate specific content without having to scan every page. In technical terms, an index is a data structure that maps keys to the physical or logical locations where corresponding records reside. When you query a database for a particular value—say, “Find all customers from New York”—the system consults the index rather than scanning the entire table, dramatically reducing the amount of work required.
Key points:
- Key‑value mapping: Each unique key (often a column or combination of columns) points to one or more storage locations.
- Speed: Indexes enable constant‑time or logarithmic‑time lookups, far faster than linear scans.
- Space: While indexes improve read speed, they also consume additional storage because they store the mapping information themselves.
How Indexes Work Under the Hood
1. B‑Tree and B+‑Tree Structures
Most relational database systems employ B‑Tree or B+‑Tree indexes because of their balanced performance for insertions, deletions, and searches. These trees maintain sorted order and keep data pages roughly half full, which minimizes the frequency of costly page splits.
- Root page: Holds pointers to child pages.
- Intermediate pages: Continue the branching until the leaf level is reached. - Leaf pages: Store the actual key‑record pointers (or the full record in a covering index).
2. Hash Indexes
For equality searches on exact matches, hash indexes can provide O(1) lookup time. A hash function converts a key into a bucket number, directly pointing to the storage location. However, hash indexes are less flexible for range queries (e.g., “greater than” or “between”).
3. Bitmap Indexes
In data warehouses with low‑cardinality columns (few distinct values), bitmap indexes compress sets of rows into bit‑vectors, allowing efficient boolean operations across multiple conditions.
Types of Indexes You’ll Encounter
| Index Type | Typical Use Case | Advantages | Limitations |
|---|---|---|---|
| Primary Key Index | Uniquely identifies each row | Guarantees uniqueness; often clustered | Must be unique; can cause overhead on inserts |
| Clustered Index | Rows stored in the order of the index | Improves range scans; reduces I/O | Only one per table; frequent updates can fragment data |
| Non‑Clustered Index | Secondary lookups on frequently queried columns | Multiple per table; can cover many columns | Additional storage; may require lookups to the base table |
| Unique Index | Enforces uniqueness without being the primary key | Prevents duplicate values; can improve join performance | Same constraints as primary key index |
| Full‑Text Index | Searching large text fields | Enables keyword, phrase, and linguistic searches | Not suitable for numeric or structured queries |
Why the Index Is the Address of Data: Practical Implications
-
Performance Gains
- Example: A table with 10 million rows may require seconds to scan for a single value without an index, but with an index on the searched column, the lookup can be completed in milliseconds.
- Impact: Faster response times improve user satisfaction and enable real‑time analytics.
-
Resource Efficiency
- By reducing the number of disk reads, indexes lower I/O pressure, which is especially critical in environments where storage access is expensive or limited.
-
Scalability
- As data volumes grow, indexes allow the system to maintain consistent query latency without a proportional increase in computational resources. 4. Data Integrity
- Indexes enforce constraints such as uniqueness and referential integrity, ensuring that the underlying data remains consistent.
Common Misconceptions About Indexes
- “More indexes always mean faster queries.” In reality, each additional index consumes write time during INSERT/UPDATE/DELETE operations and occupies storage space. Over‑indexing can degrade overall system performance.
- “Indexes are only for large databases.” Even small tables benefit from indexes when queries involve specific columns repeatedly.
- “Indexes store the actual data.” Most indexes store only pointers (the “address”) to the data, not the data itself, except for covering indexes that include selected columns.
Frequently Asked Questions
Q: Can an index be created on multiple columns?
A: Yes. A composite index combines several columns into a single index, enabling efficient queries that filter on any prefix of those columns.
Q: What happens if I update a column that is part of an index?
A: The index entry must be updated as well, which can add overhead. Frequent updates to indexed columns may necessitate rebuilding the index periodically.
Q: Are indexes used in NoSQL databases?
A: Many NoSQL systems, such as MongoDB and Cassandra, support secondary indexes, though their implementation and performance characteristics can differ from relational databases.
Q: How do I decide which columns to index?
A: Focus on columns that are frequently used in WHERE, JOIN, ORDER BY, or GROUP BY clauses, especially those with high selectivity (i.e., they filter out a large portion of rows).
Conclusion
The index is the address of a piece of data, a concept that bridges logical queries and physical storage. By acting as a meticulously crafted map, an index transforms what could be a laborious full‑table scan into a swift, targeted lookup. This transformation not only accelerates response times but also conserves computational resources, making large‑scale data management feasible. However, indexes are a double‑edged sword: they demand careful design, periodic maintenance, and a balanced trade‑off between read speed and write overhead. Mastering the art of indexing empowers developers, analysts, and administrators to unlock the full potential of their data, ensuring that information is not only abundant but also readily accessible when it matters most.
Conclusion
The index is the address of a piece of data, a concept that bridges logical queries and physical storage. By acting as a meticulously crafted map, an index transforms what could be a laborious full-table scan into a swift, targeted lookup. This transformation not only accelerates response times but also conserves computational resources, making large-scale data management feasible. However, indexes are a double-edged sword: they demand careful design, periodic maintenance, and a balanced trade-off between read speed and write overhead. Mastering the art of indexing empowers developers, analysts, and administrators to unlock the full potential of their data, ensuring that information is not only abundant but also readily accessible when it matters most.
In essence, understanding and applying indexing strategies is a fundamental skill for anyone working with relational databases. It's about optimizing for performance without sacrificing data integrity or incurring unnecessary costs. By thoughtfully managing indexes, organizations can gain a significant competitive advantage in today's data-driven world, enabling faster insights, improved operational efficiency, and ultimately, better decision-making. The key lies in recognizing that indexing is not a "set it and forget it" solution, but rather an ongoing process of analysis, tuning, and refinement.
Beyondthe basic rule of indexing columns that appear in filter, join, sort, or group clauses, effective indexing strategy also hinges on understanding the underlying index structures and how they interact with query patterns.
Choosing the right index type
Most relational systems default to B‑tree indexes because they support equality, range, and prefix lookups efficiently. However, specialized workloads can benefit from alternatives:
- Hash indexes excel at exact‑match equality checks but cannot handle range scans or ORDER BY.
- Bitmap indexes are advantageous in data‑warehouse environments where columns have low cardinality and queries combine many predicates via AND/OR.
- GIN/GiST indexes (PostgreSQL) or full‑text indexes cater to semi‑structured data, JSONB, arrays, or text search, enabling rapid containment or similarity tests that B‑trees cannot provide.
Composite indexes and column order
When a query frequently references multiple columns together, a composite index can be far more effective than several single‑column indexes. The order of columns matters: place the most selective column (the one that filters out the largest fraction of rows) first, followed by columns used for equality checks, then those needed for sorting or grouping. This arrangement lets the engine traverse the index tree with minimal backtracking and often eliminates the need for a separate sort step.
Covering indexes and included columns
If an index contains all columns required by a query—either as key columns or as non‑key “included” columns—the engine can satisfy the request purely from the index leaf pages, avoiding a costly lookup to the base table (a technique known as an index‑only scan). Adding frequently selected but non‑filter columns as included columns can boost read performance while keeping the index size modest compared with making them part of the key.
Partial and filtered indexes
For tables where a significant subset of rows is rarely queried (e.g., archived orders, inactive users), a partial index that indexes only rows meeting a predicate (WHERE status = 'active') can dramatically reduce index size and maintenance overhead while still speeding up the relevant queries.
Monitoring and maintenance
Indexes are not static objects. Over time, insertions, updates, and deletions can cause page splits, fragmentation, and stale statistics, all of which degrade performance. Regularly:
- Review usage statistics (e.g., pg_stat_user_indexes, sys.dm_db_index_usage_stats) to identify unused or rarely used indexes that are candidates for removal.
- Analyze query plans with EXPLAIN (ANALYZE, BUFFERS) to verify that the optimizer is actually using the intended index and to detect unexpected scans.
- Rebuild or reorganize indexes based on fragmentation thresholds; many systems offer online rebuild options that minimize downtime.
- Update statistics so the planner has accurate selectivity estimates, which directly influences index choice.
Balancing read and write costs
Every index adds overhead to INSERT, UPDATE, and DELETE operations because each modification must propagate to all affected indexes. In write‑intensive workloads, it is prudent to:
- Limit the number of indexes per table to those with demonstrable read benefit.
- Consider using index‑only tables or materialized views for reporting queries that can tolerate slightly stale data.
- Employ partitioning alongside indexing; smaller partitions mean smaller indexes, which reduces both query and maintenance costs. Practical workflow
- Baseline – Capture current query performance and index usage.
- Hypothesize – Identify candidate columns or column combinations based on query patterns.
- Implement – Create the index concurrently (if supported) to avoid blocking writes.
- Validate – Run the workload again, compare execution times, and inspect plans.
- Iterate – Retain indexes that show measurable gain; drop those that do not.
By treating indexing as a continual loop of measurement, adjustment, and validation, teams can keep their databases agile, responsive, and cost‑effective as data volumes
Advanced considerations and emerging trends
As data sizes continue to expand, static index designs often prove insufficient. Modern database platforms now support expression indexes, functional indexes, and JSON/GIS indexes, allowing you to index computed values or nested fields without duplicating entire rows. For example, an expression index on LOWER(email) can accelerate case‑insensitive lookups while preserving the original case‑sensitivity for other queries.
Another powerful avenue is adaptive indexing built into some cloud‑native engines. These systems monitor query patterns in real time and automatically create or drop indexes based on observed workload shifts. While this reduces the manual overhead of index management, it still requires guardrails: setting thresholds, defining safe drop windows, and ensuring that auto‑generated indexes do not inadvertently lock writes during their creation.
Hybrid indexing strategies
In hybrid transactional/analytical processing (HTAP) environments, a common pattern is to keep a narrow set of transactional indexes for OLTP efficiency while maintaining columnar or bitmap indexes for OLAP workloads. Columnar stores excel at aggregations over large datasets, and bitmap indexes provide fast filtering on low‑cardinality attributes such as gender or region. By separating the index families along the transactional‑analytical boundary, you avoid the costly cross‑contamination of write‑heavy and read‑heavy index maintenance.
Index compression and storage engines
Many DBMSs now offer built‑in compression for index pages, dramatically reducing I/O without sacrificing lookup speed. In PostgreSQL, for instance, the BRIN (Block Range INdex) type can be combined with ZLIB compression to shrink indexes on append‑only tables, while MySQL’s InnoDB supports COMPRESSED secondary indexes. Selecting the appropriate compression algorithm and level can yield a 30‑50 % reduction in index footprint, especially for high‑cardinality numeric keys.
Security‑aware indexing
When dealing with personally identifiable information (PII), indexes that expose raw values can become a compliance liability. Some databases now support encrypted indexes or deterministic encryption for specific columns, allowing equality searches while keeping the underlying data encrypted at rest. Although encrypted indexes are generally slower than their plaintext counterparts, they enable organizations to meet stringent data‑privacy regulations without sacrificing query capability.
Automation and governance
To keep indexing efforts sustainable at scale, teams are adopting Infrastructure‑as‑Code (IaC) patterns for index definitions. Storing CREATE INDEX statements in version‑controlled repositories enables peer review, change tracking, and rollback capabilities. Coupled with CI/CD pipelines that run performance regression tests after each schema change, this approach ensures that index modifications are validated before they reach production.
Conclusion
Indexing remains a delicate balancing act between accelerating reads and preserving write efficiency. By thoughtfully selecting the right index type — whether B‑tree, hash, GIN, BRIN, or expression‑based — tailoring it to the query’s selectivity, and continuously monitoring its impact, you can extract maximum performance from your data store. Embracing automated monitoring, hybrid storage models, and modern compression techniques further refines this process, while strict governance safeguards against unintended side effects. When approached as an iterative, data‑driven discipline rather than a one‑time configuration, indexing becomes a strategic asset that scales gracefully alongside your growing data volumes.
Latest Posts
Latest Posts
-
Catcher In The Rye Chapter Analysis
Mar 24, 2026
-
Is Quran The Same As Bible
Mar 24, 2026
-
Catcher In The Rye Chapter 1 Summary
Mar 24, 2026
-
Catcher In The Rye Chapter Summary
Mar 24, 2026
-
As I Lay Dying Plot Summary
Mar 24, 2026